Spark 学习之运行架构与主要流程
1. 基础概念学习
在学习下面的 Spark 运行架构和原理之前,还需要先大致了解下Spark的一些基本概念和组件:
1.1 Application (应用程序)
一个独立的单位,代表了用户提交给Spark执行的一个任务或作业。
每个应用程序都由一个驱动程序(Driver Program)启动,并且拥有自己的执行上下文。
1.2 Driver Program (驱动程序)
这是运行在客户端的应用程序的主要进程,主要负责创建SparkContext。
驱动程序定义了应用程序的逻辑,包括创建RDD、转换操作和触发actions。
它也负责将作业划分为多个阶段(Stages),并监控这些阶段的执行情况。
1.3 Cluster Manager (集群管理器)
管理整个集群资源分配的组件。
负责启动Executor并分配资源给它们。
Spark可以与多种集群管理器集成,例如YARN, Mesos, Kubernetes, 或者Spark自带的Standalone模式。
1.4 Worker Node (工作节点)
集群中的每个机器都是一个工作节点。
工作节点上运行着Executor进程,执行具体的任务。
Worker节点会向集群管理器注册,并报告自身可用的资源。
1.5 Executor (执行器)
在每个工作节点上为特定应用程序运行的进程。
Executor负责运行Task,并且维护应用程序的状态信息,比如缓存数据。
多个Executor可以在同一台机器上运行,但每个Executor属于不同的应用程序。
1.6 RDD (Resilient Distributed Datasets,弹性分布式数据集)
RDD 本质上是 Spark 的核心编程抽象,它代表一个不可变、分区的数据集合,可以在集群中的多个节点上进行并行操作。以下是关于RDD的一些关键点:
不可变性 (Immutable): 一旦创建了RDD,其内容就不能被改变。所有的转换操作都会生成新的RDD。
分区 (Partitioned): RDD逻辑上被划分为多个分区,这些分区可以分布在不同的机器上,允许并行处理。
容错性 (Fault-Tolerant): RDD通过记录每个数据集是如何从其他数据集转化而来的方式(即血缘关系或lineage)来实现容错。如果某个RDD丢失,可以通过重算之前的转换来恢复。
惰性求值 (Lazy Evaluation): RDD上的转换操作不会立即执行,而是等到遇到动作(action)时才会触发实际的计算。
位置感知调度 (Location-Aware Scheduling): Spark尝试将任务分配到存储该任务所需数据的节点上运行,以减少网络传输开销。
持久化 (Persistence): 可以选择将RDD缓存到内存或者磁盘中,以便后续快速访问。
1.7 DAG (Directed Acyclic Graph)
DAG 在Spark中用来表示作业的执行计划。当用户定义了一系列的转换操作后,Spark会构建一个逻辑执行计划,这个计划就是DAG。以下是关于DAG的一些关键点:
DAG的构建: 当用户调用map, filter, reduceByKey等transformation方法时,Spark并不会立即执行这些操作,而是记录下这些操作。直到用户调用一个action(如collect, count等),Spark才会根据之前记录的操作构建DAG,并开始执行。
Stage划分: DAG由多个Stage组成,每个Stage是一组可以并行执行的任务(Tasks)。Stage之间的边界通常是在发生Shuffle操作时划定的。Shuffle是一种需要重新分布数据的过程,比如groupByKey或reduceByKey等操作。
宽依赖与窄依赖: 在DAG中,RDD之间有两种类型的依赖关系:
窄依赖 (Narrow Dependency): 每个父RDD的partition最多被子RDD的一个partition使用。例如,map和filter产生的是窄依赖。
宽依赖 (Wide Dependency): 子RDD的partition可能依赖于父RDD的所有partition。例如,groupByKey和reduceByKey产生的是宽依赖。
优化: Spark使用DAG来进行一系列优化,包括避免不必要的Shuffle操作、合并连续的小任务以减少启动开销等。
执行: 一旦DAG构建完成,Spark就会按照Stage顺序依次执行,每个Stage内部的任务可以并行执行。在宽依赖处,由于需要Shuffle,所以会在Stage之间插入一个Barrier,确保前一个Stage的所有任务都完成后才开始下一个Stage。
1.8 Task (任务)
Task是最小的工作单元,它对应于对分区数据进行的操作。
每个Task都会被发送到Executor去执行,而结果会被返回给驱动程序或写入外部存储系统。
通常,一个Stage内的所有Tasks是相同的,只是作用于不同的数据分区。
1.9 Job (作业)
一次action触发一个Job,它是从开始到结束的一系列操作。
Job是由一系列Stage组成的,每个Stage包含一组相关的Tasks。
1.10 Stage (阶段)
一个Job被分解成多个Stage来执行。
Stage是由相同的Shuffle依赖关系划分的任务组。
如果没有Shuffle,则可以形成一个宽依赖;如果有Shuffle,则会形成窄依赖,进而划分成新的Stage。
Stage内部的任务可以并行执行,但是不同Stage之间需要按照顺序执行。
2. Spark 集群运行架构
Spark 是基于内存计算的大数据并行计算框架,比 MapReduce 计算框架具有更高的实时性,同时具有高效容错性和可伸缩性,下图为 Spark 的运行架构:
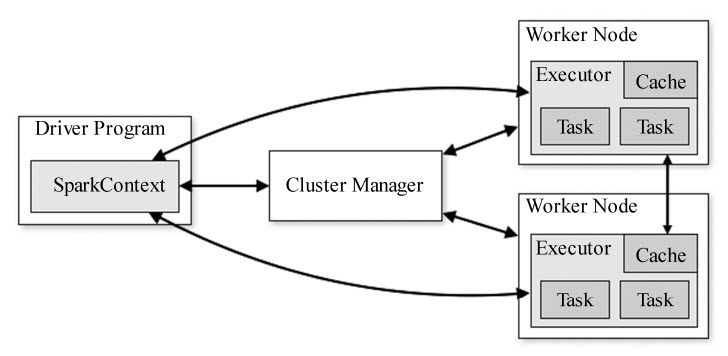
Spark 应用在集群上运行时,包括了多个独立的进程,这些进程之间通过 Driver Program 中的 SparkContext 对象进行协调,SparkContext 对象支持与多种集群资源管理器(Cluster Manager)通信,一旦与集群资源管理器连接,Spark 会为该应用在各个集群节点上申请执行器(Executor),用于执行计算任务和存储数据。Spark将应用程序代码发送给所申请到的执行器,SparkContext对象将分割出的任务(Task)发送给各个执行器去运行。
每个 Spark 应用程序都有其对应的多个执行器进程。从调度角度来看,每个驱动程序(Driver Program)可以独立调度本应用程序的内部任务;从执行器角度来看,不同Spark应用对应的任务将会在不同的JVM中运行。
Spark 的驱动程序在整个生命周期之内必须监听并接受其对应的各个执行器的连接请求,因此也就能够被所有 Worker 节点访问。
3. Spark 的运行流程
下图为 Spark 运行的基本流程:
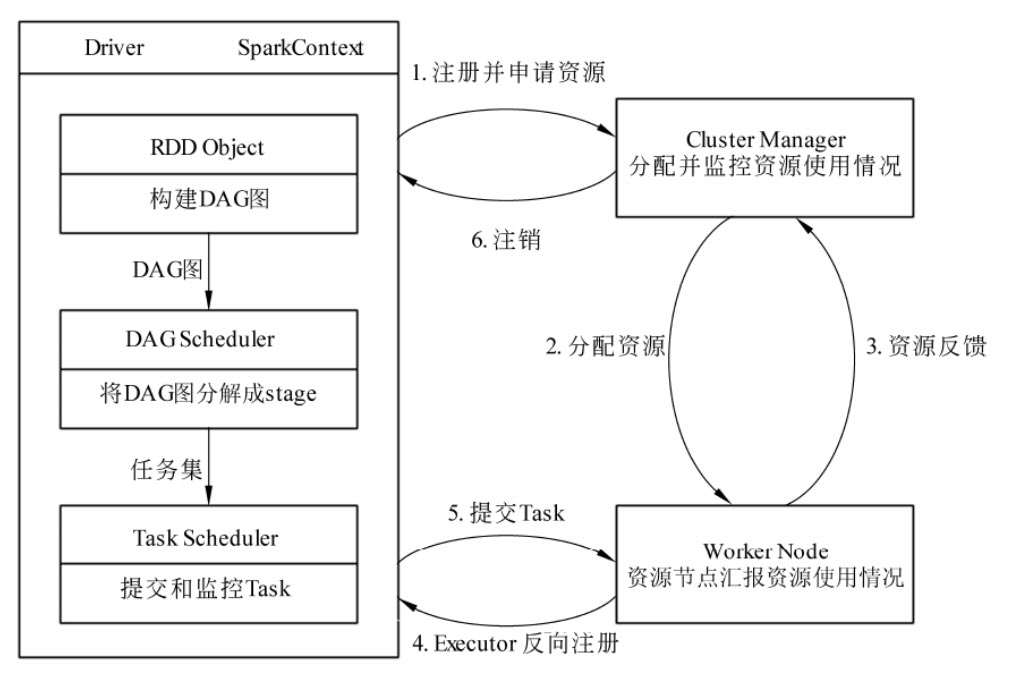
当一个 Spark 应用被提交时,根据提交参数在相应位置创建 Driver 进程,Driver 进程根据配置参数信息初始化 SparkContext 对象,即 Spark 运行环境,由 SparkContext 负责和 Cluster Manager 的通信以及资源的申请、任务的分配和监控等。SparkContext 启动后创建 DAG Scheduler(将 DAG 图分解成 Stage)和 Task Scheduler(提交和监控 Task)两个调度模块;
Driver 进程根据配置参数向 Cluster Manager 申请资源(主要是用来执行的 Executor),Cluster Manager 接收到应用(Application)的注册请求后,会使用自己的资源调度算法,在 Spark 集群的 Worker 节点上,通知 Worker 为应用启动多个 Executor;
Executor 创建后,会向 Cluster Manager 进行资源及状态的反馈,便于 Cluster Manager 对 Executor 进行状态蓝控,如果监控到 Executor 失败,则会立刻重新创建。
Executor 会向 SparkContext 反向注册申请 Task。
Task Scheduler 将 Task发送给 worker 进程中的 Executor 运行并提供应用程序代码。
当程序执行完毕后写人数据,Driver 向 Cluster Manager 注销申请的资源。
4. 运行示例
这里以一个基于 pyspark 的示例程序为例,
bin/spark-submit \
--master yarn \
--deploy-mode client \
--executor-memory 4G \
--driver-memory 4G \
~/dim_iot_device_etl.py上述命令在 Spark 目录下执行:
--master yarn:指定将应用提交到 Yarn 集群上运行;
--deploy-mode client:指定客户端模式,即在提交 Spark 应用时,表示在本地运行;
--executor-memory 和 --driver-memory:指定每个执行器和驱动程序的内存大小;
这里将一个 dim_iot_device_etl.py 脚本提交到 Spark 上运行,因为该示例脚本是在本地运行的,并且提交到 Yarn 集群上,所以我们可以通过 YARN 的控制台查看运行情况,如下图:
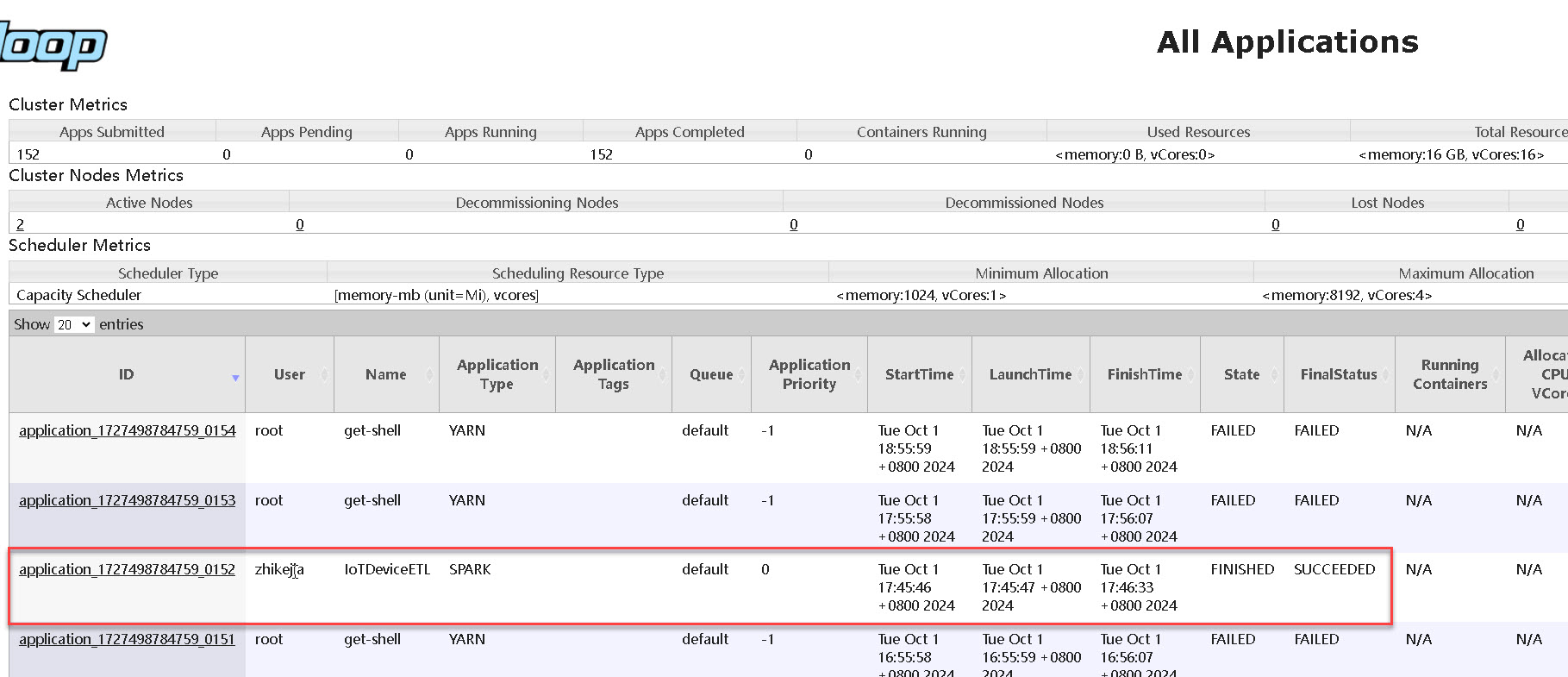
在 YARN 集群的控制台上可以看到所有的应用列表,上面的命令所提交的应用类型(Application Type)为 SPARK,在页面上还动态展示了应用的运行情况。
上面的命令执行后的部分输出如下:
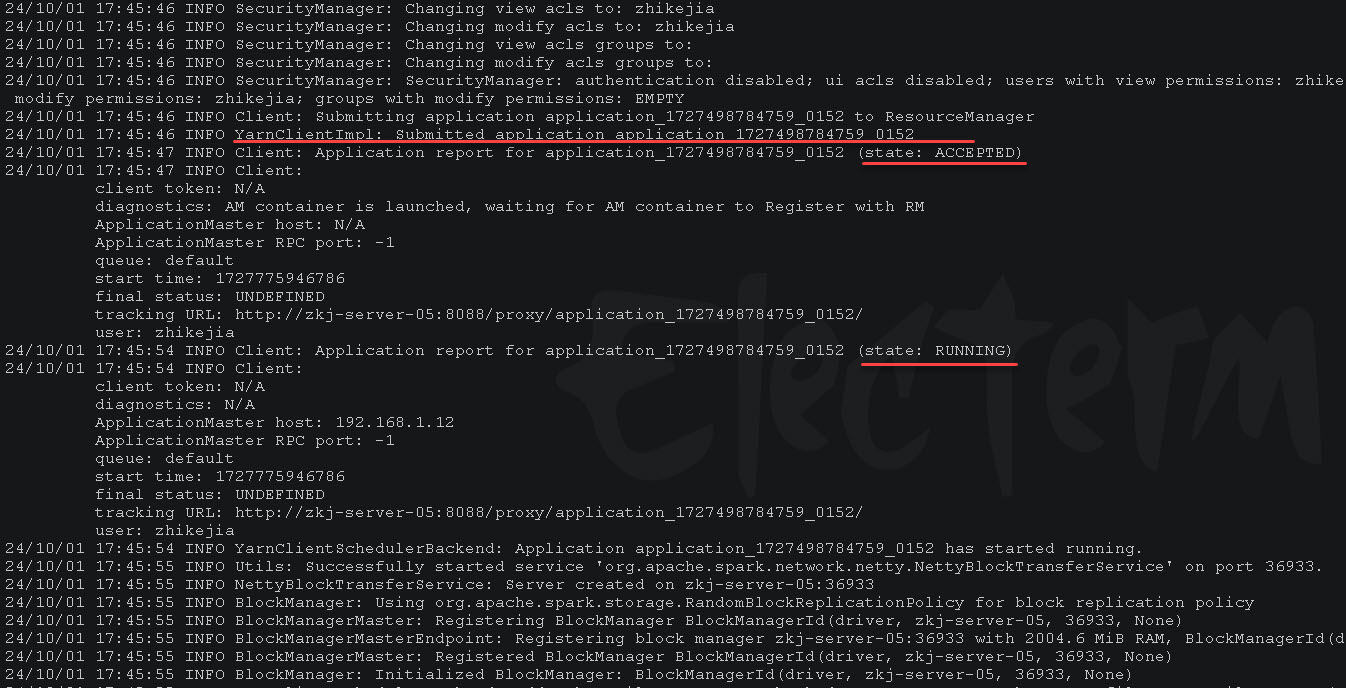
上面的日志输出展示了向 YARN 集群提交了应用 application_1727498784759_0152,应用从 ACCEPTED 状态到 RUNNING 状态。
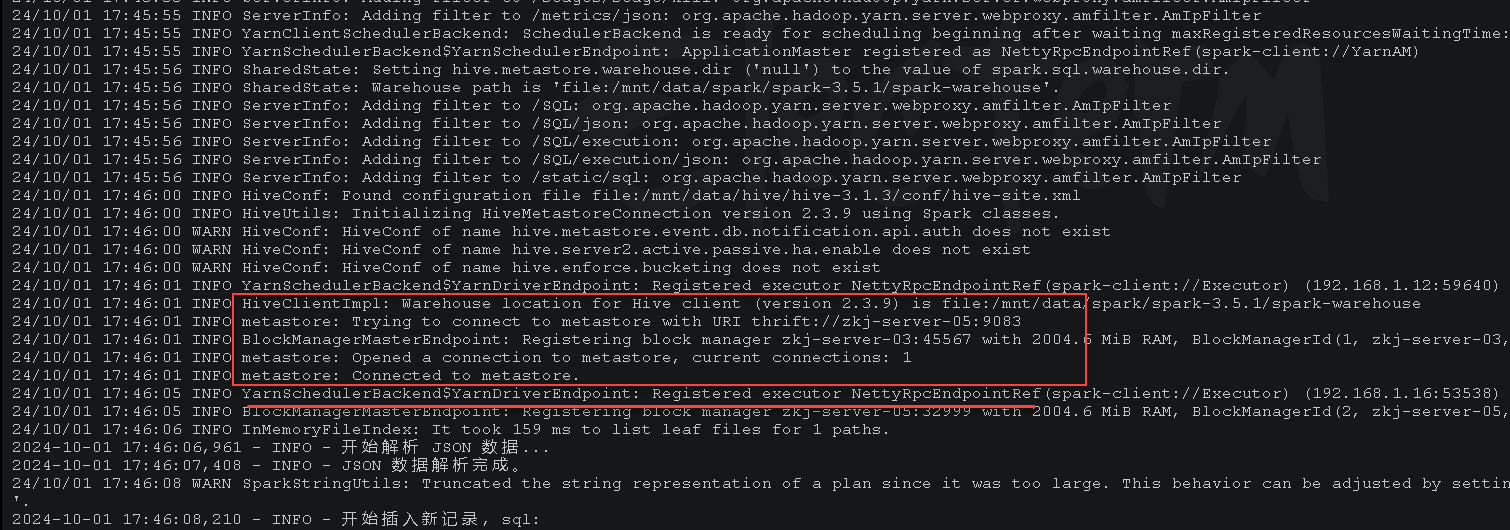
因为在 dim_iot_device_etl.py 示例脚本中需要查询和操作Hive,下面的日志输出中可以看到连接 Hive 的 metastore 服务:
下面为 dim_iot_device_etl.py 示例脚本摘取:
import logging
from pyspark.sql import SparkSession, functions as F
from pyspark.sql.types import *
# 配置日志
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s - %(message)s')
# 初始化 Spark 会话
# 并设置应用程序名称为 IoTDeviceETL
spark = SparkSession.builder \
.appName("IoTDeviceETL") \
.enableHiveSupport() \
.getOrCreate()
# 读取 ODS 表
ods_iot_device_full = spark.table("ods_iot_device_full")
ods_iot_product_full = spark.table("ods_iot_product_full")
dim_iot_device_zip = spark.table("dim_iot_device_zip")
# 将解析后的 DataFrame 注册为临时视图
ods_iot_device_full.createOrReplaceTempView("ods_iot_device_full_view")
ods_iot_product_full.createOrReplaceTempView("ods_iot_product_full_view")
dim_iot_device_zip.createOrReplaceTempView("dim_iot_device_zip_view")
# 插入新记录
new_records_sql = f"""
SELECT
d.id,
d.tenant_id,
...,
current_timestamp() AS start_date,
NULL AS end_date
FROM
ods_iot_device_full_view d
LEFT JOIN ods_iot_product_full_view p ON d.product_id = p.id
LEFT JOIN ods_iot_product_full_view p2 ON d.conn_product_id = p2.id
LEFT ANTI JOIN dim_iot_device_zip_view dim ON d.id = dim.id
"""
new_records = spark.sql(new_records_sql)
# 更新的记录
updated_records_sql = f"""
SELECT
d.id,
d.tenant_id,
...,
current_timestamp() AS start_date,
NULL AS end_date
FROM
ods_iot_device_full_view d
LEFT JOIN ods_iot_product_full_view p ON d.product_id = p.id
LEFT JOIN ods_iot_product_full_view p2 ON d.conn_product_id = p2.id
INNER JOIN dim_iot_device_zip_view dim ON d.id = dim.id
WHERE
d.sub_tenant_id != dim.sub_tenant_id OR
d.parent_id != dim.parent_id OR
d.root_id != dim.root_id OR
d.parent_endpoint != dim.parent_endpoint OR
d.conn_product_id != dim.conn_product_id OR
d.activate_time != dim.activate_time OR
d.last_online_time != dim.last_online_time OR
d.last_offline_time != dim.last_offline_time OR
d.last_login_time != dim.last_login_time OR
d.location != dim.location
"""
updated_records = spark.sql(updated_records_sql)
logging.info("更新记录完成。")
# 合并新的和更新的记录
final_df = new_records.union(updated_records)
logging.info("新的和更新的记录合并完成。")
# 创建临时表
temp_table_name = "temp_dim_iot_device_zip"
final_df.createOrReplaceTempView(temp_table_name)
# 更新旧记录的 end_date
logging.info("开始更新旧记录的 end_date...")
updated_dim_iot_device_zip_sql = f"""
WITH updated_records AS (
SELECT * FROM {temp_table_name}
)
SELECT
dim.id,
dim.tenant_id,
...,
dim.start_date,
CASE WHEN upd.start_date IS NOT NULL THEN current_timestamp() ELSE dim.end_date END AS end_date
FROM
dim_iot_device_zip_view dim
LEFT JOIN updated_records upd ON dim.id = upd.id
"""
updated_dim_iot_device_zip = spark.sql(updated_dim_iot_device_zip_sql)
logging.info("旧记录的 end_date 更新完成。")
# 将更新后的旧记录与新记录合并
final_result = final_df.union(updated_dim_iot_device_zip)
final_result.createOrReplaceTempView("final_result_view")
# 创建临时表
temp_table_name = "temp_dim_iot_device_zip_final"
final_result.write.mode("overwrite").saveAsTable(temp_table_name)
# 将临时表的数据插入到目标表
logging.info("开始写入目标表 dim_iot_device_zip...")
spark.sql(f"""
INSERT OVERWRITE TABLE dim_iot_device_zip
SELECT * FROM {temp_table_name}
""")
logging.info("目标表 dim_iot_device_zip 写入完成。")
# 停止 Spark 会话
spark.stop()
logging.info("Spark 会话已停止。")上面的 dim_iot_device_zip 维度表是采用的拉链表的设计,通过在数据中添加 start_date 和 end_date 两个字段来记录数据的变更时间,从而实现对历史数据的正确记录。