数据仓库设计之分层设计
1. 概述
数据仓库的分层设计是一种常见的架构方法,它通过将数据组织成多个层次,以支持数据的整合、管理和分析。分层设计有助于简化数据管理,提高数据的可维护性和可扩展性。
2. 分层设计
典型的分层设计包括 ODS(Operational Data Store)、DIM(Dimension)、DWD(Data Warehouse Detail)、DWS(Data Warehouse Summary)、ADS(Application Data Store)等层次。下面详细讲解这些层次的主要功能以及它们之间的关系。
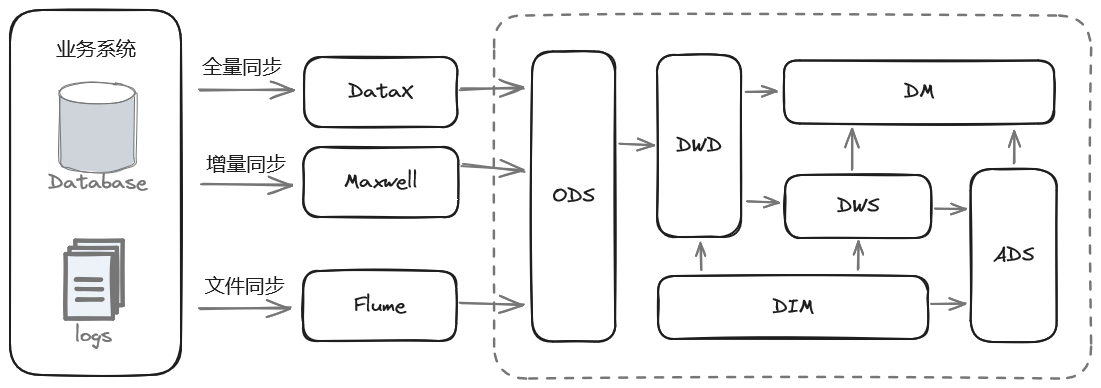
2.1 ODS(Operational Data Store,操作数据存储层,也称为贴源层)
ODS是数据仓库的最底层,是最接近数据源的数据层,主要功能是接收来自不同数据源(如业务数据库、日志文件、外部API等)未经处理的原始数据。
数据在这个层面上通常不做过多的处理,除了必要的去噪(如去除明显的错误数据)、去重、数据类型转换和字段名称规范化等基本的清洗操作,以保持数据的原始性。
ODS 用来隔离数据源与后续处理层,可以使得数据源的结构变化不会直接影响到其他层,同时也为后续的数据处理提供基础数据。
2.1.1 主要功能
近实时数据存储:ODS 层通常用于存储来自业务系统的近实时数据,数据更新频率较高。
原始数据保留:ODS 层保留了从源系统抽取的原始数据,不做过多的数据清洗和转换。
数据校验与初步清洗:进行简单的数据校验和初步清洗,以确保数据的质量。
支持查询:提供对近实时数据的查询支持,满足一些需要快速响应的业务需求。
2.1.2 主要特点
数据更新频繁。
数据结构接近源系统。
存储周期较短,一般为几天到几周。
2.2 DIM(Dimension,维度层)
在数据仓库系统中,DIM层(Dimension Layer)主要用于存储维度数据,这些数据提供了描述性信息,以支持对事实数据的理解和分析。
通过结合 DIM 层的维度表与事实表,提供丰富的上下文信息,增强数据分析的维度和深度。
2.2.1 主要功能
维度数据存储:DIM 层存储维度表,包含描述性的信息,如时间、地点、客户、产品等。
一致性维度:确保维度数据的一致性,避免在不同事实表中出现不一致的维度数据。
缓慢变化维处理:处理维度数据的缓慢变化,记录历史变化信息。
2.2.2 主要特点
数据更新相对较少,如属性描述,不随时间频繁变更。
维度表通常较小,但非常重要。
维度表中的数据经常被引用,因此需要优化查询性能。
2.3 DWD(Data Warehouse Detail,数据仓库明细层)
DWD 层是数据仓库架构中的一个重要层次,它位于数据仓库的较高层次,通常在 ODS 和 DIM 层之上,DWS 之下。DWD层的主要目的是存储经过清洗、整合和轻度汇总的明细数据,以支持企业的日常运营报告和详细分析。
2.3.1 主要功能
明细数据存储:DWD 层存储经过清洗和转换后的明细数据,是数据仓库的核心层。
数据清洗与转换:进行详细的数据清洗、转换和标准化,确保数据质量。
历史数据保留:保留历史数据,支持时间序列分析和趋势分析。
粒度保持:保持数据的细粒度,支持详细的分析和查询。
2.3.2 主要特点
数据量较大。
数据更新频率较低,通常是每天或每周一次。
提供详尽的数据细节,支持复杂的分析需求。
2.4 DWS(Data Warehouse Summary,数据仓库汇总层)
DWS 层的主要目的是对 DWD 层的明细数据进行轻度汇总和预聚合,以支持更高效的查询和分析。在实际的数据仓库设计中,DWS层的设计需要考虑业务需求、数据使用模式和性能要求,以确保它能够有效地支持企业的数据分析和决策制定。
2.4.1 主要功能
2.4.1.1 轻度汇总
预聚合:对 DWD 层的明细数据进行轻度汇总,生成一些常用的中间结果,如日汇总、周汇总、月汇总等。
减少计算量:通过预先计算和存储这些汇总数据,可以减少后续查询时的计算量,提高查询性能。
2.4.1.2 多维分析支持
支持 OLAP:DWS 层的数据结构通常适合进行在线分析处理(OLAP),支持复杂的多维分析和报表生成。
星型模型和雪花模型:DWS 层的数据结构通常是星型或雪花模型,便于进行多维分析。
2.4.1.3 数据服务
提供高性能数据访问:DWS 层的数据经过优化,能够快速响应查询请求,支持 BI 工具和报表系统的高效访问。
数据一致性:确保数据的一致性和准确性,为上层应用提供可靠的数据服务。
2.4.1.4 历史数据保留
保留历史汇总数据:DWS 层会保留一定时间范围内的历史汇总数据,支持趋势分析和时间序列分析。
2.4.1.5 灵活的数据视图
定制化视图:根据不同的业务需求,DWS 层可以提供多种定制化的数据视图,满足不同用户的查询需求。
2.4.2 主要特点
数据粒度
介于 DWD 和 ADS 之间:DWS 层的数据粒度比 DWD 层粗,但比 ADS 层细。它保留了一定的细节,同时进行了轻度汇总。
更新频率
较低的更新频率:DWS 层的数据更新频率通常较低,可能是每天或每周一次,具体取决于业务需求。
数据质量
高质量数据:DWS 层的数据经过了 DWD 层的清洗和转换,确保了数据的质量和一致性。
性能优化
索引和分区:为了提高查询性能,DWS 层的数据通常会使用索引和分区技术。
压缩:使用高效的压缩算法,减少存储空间需求并提高 I/O 性能。
可扩展性
易于扩展:DWS 层的设计考虑了未来的扩展需求,可以方便地添加新的汇总表和维度。
2.5 ADS(Application Data Store, 应用数据层)
ADS 层主要面向特定的应用程序或业务场景,提供高度定制化的数据视图和服务。ADS 层的数据通常是经过高度汇总和加工的,目的是为前端应用提供快速、高效的数据访问。
2.5.1 主要功能
高度汇总:
深度聚合:对 DWS 层的数据进行进一步的高度汇总,生成高度聚合的数据集。
减少计算量:通过预先计算和存储这些高度汇总的数据,减少查询时的计算量,提高响应速度。
面向应用:
定制化数据视图:根据具体的应用需求,提供定制化的数据视图,满足不同业务场景的需求。
支持实时或近实时数据访问:为前端应用提供实时或近实时的数据访问,支持动态报表和仪表盘。
数据服务:
API 接口:提供 API 接口,供前端应用调用,实现数据的快速获取。
数据推送:支持数据推送机制,将数据主动推送到前端应用,减少轮询带来的性能开销。
报表和仪表盘:
报表生成:支持生成各种报表,如销售报表、财务报表等。
仪表盘展示:提供直观的数据可视化,支持 KPI 监控和业务分析。
2.5.2 主要特点
数据粒度:
最粗的数据粒度:ADS 层的数据粒度通常是最粗的,适合高层决策和报表展示。
更新频率:
较高的更新频率:ADS 层的数据更新频率较高,可能是近实时的,以支持动态报表和实时监控。
数据质量:
高质量数据:ADS 层的数据经过了 DWD 和 DWS 层的清洗、转换和轻度汇总,确保了数据的质量和一致性。
性能优化:
索引和分区:为了提高查询性能,ADS 层的数据通常会使用索引和分区技术。
压缩:使用高效的压缩算法,减少存储空间需求并提高 I/O 性能。
缓存:使用缓存技术,提高数据访问速度。
可扩展性:
易于扩展:ADS 层的设计考虑了未来的扩展需求,可以方便地添加新的数据视图和接口。
安全性:
权限控制:提供细粒度的权限控制,确保数据的安全性和隐私保护。
3. 分层关系
3.1 ODS -> DWD
ODS 层的数据经过清洗和转换后进入 DWD 层,形成详细的、高质量的数据。
ODS 层的数据通常是近实时的,而 DWD 层的数据更新频率较低。
3.2 DWD -> DWS
DWD 层的明细数据经过轻度汇总后进入 DWS 层,形成轻度汇总的数据。
DWS 层的数据粒度较 DWD 层粗,但仍然保持一定的细节,支持多维分析。
3.3 DWS -> ADS
DWS 层的数据经过进一步的高度汇总后进入 ADS 层,形成高度汇总的数据。
ADS 层的数据粒度最粗,适合高层决策和报表展示。
3.4 DIM 层
DIM 层的维度数据可以被 DWD、DWS 和 ADS 层引用,确保维度数据的一致性。
维度表通常在 DWD 层生成,并在整个数据仓库中共享使用。