Apache Airflow 的工作流编排学习
Apache Airflow 是一个用于创建、监控和调度工作流的开源平台。它允许用户以编程方式设计复杂的管道,并通过直观的用户界面来管理这些管道。

在现代数据处理和分析领域,工作流编排工具扮演着至关重要的角色,特别是在那些需要自动化和大规模数据处理的工作环境中。Apache Airflow,作为一个强大的工作流编排平台,提供了一个简单而灵活的方式来定义、调度和监控数据工作流。
1. Airflow中的基础概念
DAG (Directed Acyclic Graph): 这是 Airflow 中的核心概念,用来描述任务之间的依赖关系。每个 DAG 都是一个 Python 类,它定义了要执行的任务以及它们的顺序。
Operator: 每个任务都是由 Operator 定义的,Operator 封装了具体的操作逻辑,如执行 SQL 查询、传输文件等。
Task: Task 是 DAG 中的一个节点,可以是一个简单的操作或是一个更复杂的子流程。
Executor: 负责启动任务实例的进程或线程,可以配置为本地执行或分布式集群执行。
Scheduler: 负责根据时间计划和依赖关系来触发任务的执行。
2. 主要特性
2.1 工作流即代码
Airflow 允许用户通过编写 Python 脚本来定义工作流(DAG)。这种方式使得工作流的设计和维护变得更加直观和方便,同时也便于版本控制。
DAGs 可以被组织成模块化的组件,使得大型项目易于管理和扩展。
2.2 强大的调度功能
Airflow 内置了一个调度程序,可以根据定义的时间表(如每小时、每天等)自动触发任务的执行。
用户可以根据需求设置自定义的日程安排,甚至可以基于事件触发任务(例如,当某个文件到达时触发任务)。
2.3 丰富的操作符(Operators)
Airflow 提供了大量的内置操作符,涵盖了常见的数据处理场景,如执行 SQL 查询、传输文件、发送电子邮件等。
用户也可以自定义操作符来满足特定的需求,或者通过社区贡献的插件来扩展功能。
2.4 直观的用户界面(UI)
Airflow 提供了一个基于 Web 的用户界面,用户可以方便地查看 DAG 的结构、状态以及历史运行记录。
通过 UI 可以对任务进行暂停、恢复、重跑等操作,并且可以查看详细的日志和性能指标。
2.5 健壮的监控与警报机制
Airflow 支持通过多种方式监控任务的状态,包括但不限于 Web UI、邮件通知、Slack 机器人等。
当任务失败或达到特定条件时,Airflow 可以自动发送警报给指定的联系人或系统。
2.6 高度的可扩展性和灵活性
Airflow 设计为高度可扩展,支持多种存储后端(如 SQLite, MySQL, PostgreSQL)和执行器(如 LocalExecutor, CeleryExecutor 等)。
用户可以根据自己的基础设施选择合适的后端和执行策略。
2.7 多租户支持
Airflow 支持多用户环境下的工作流管理,每个用户可以有自己的工作空间,并且可以控制访问权限。
2.8 安全性
Airflow 支持多种认证机制,如 LDAP、OAuth2 等,确保只有授权用户才能访问系统。
数据加密、审计日志等功能也增强了系统的安全性。
2.9 集成能力
Airflow 可以很容易地与其他工具和服务集成,比如 Kubernetes、Cloud Storage 解决方案等,从而支持更加广泛的应用场景。
2.10 社区与文档
Airflow 拥有一个活跃的社区,持续贡献新功能和插件,同时提供了详尽的官方文档和教程来帮助用户快速上手。
3. 实践案例
在实际的数据仓库以及大数据系统中,会涉及到多个流程步骤,如:
数据提取 (Extract): 从外部 API 或数据库获取数据。
数据转换 (Transform): 清洗数据并进行特征工程。
数据加载 (Load): 将处理后的数据加载到另一个存储系统(如 HDFS 或 S3)。
训练模型 (Train Model): 使用处理好的数据来训练机器学习模型。
评估模型 (Evaluate Model): 对模型进行评估,并决定是否部署。
部署模型 (Deploy Model): 将模型部署到生产环境。
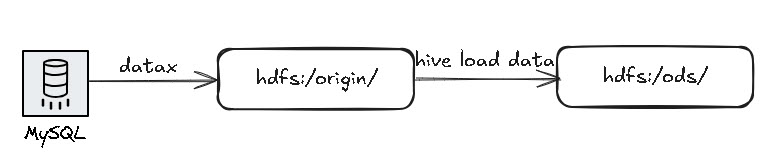
我们需要构建一个从 MySQL 数据库的一张表获取数据,写入 HDFS 的 origin 的对应目录下,之后再通过 Hive HQL Load Data 命令将数据加载到 Hive 数据仓库的指定表中, 下面我们通过这个流程在 Airflow 上来演示这个工作流的实现。
3.1 运行环境
本文跳过 Hadoop、Hive 以及 Airflow 的安装过程,下面示例中的 airflow 是以 standalone 模式运行的,主要是为了演示通过 DAG 配置工作流。下面为本文的示例运行的各个系统的版本:
另外,示例中涉及到连接 HDFS 和 Hive,因此也需要安装好对应的 providers,如下图:
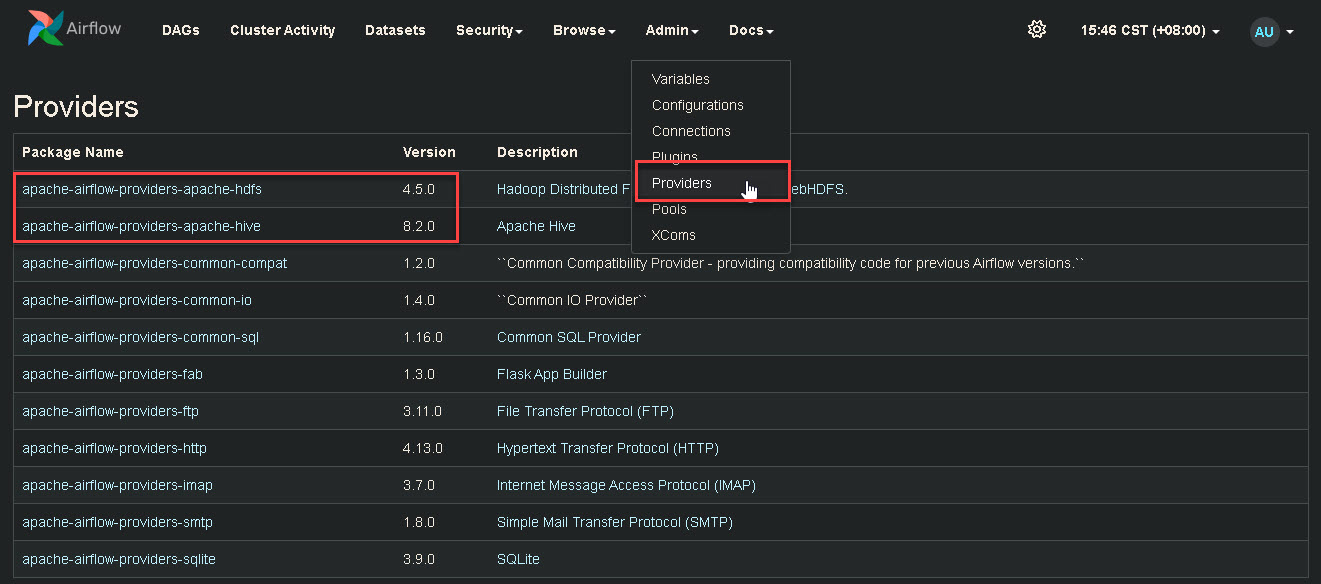
参考命令(具体版本可以自行指定):
pip install apache-airflow-providers-apache-hdfs --break-system-packages
pip install apache-airflow-providers-apache-hive --break-system-packages
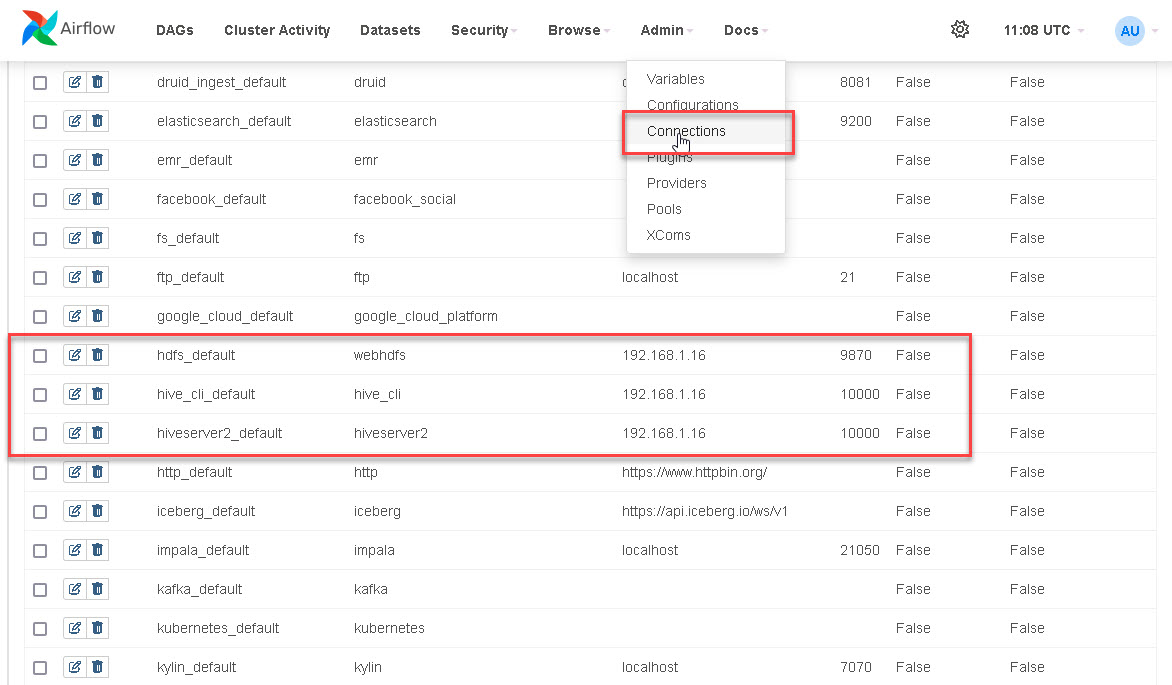
3.2 配置连接 Connection
在 Airflow 控制台上配置 HDFS 和 Hive 的连接参数,如下图:
3.3 编写和部署 DAG
DAG(有向无环图,Directed Acyclic Graph)是 Apache Airflow 的核心概念之一,它用来定义一系列任务及其相互间的依赖关系。每一个 DAG 都是一个 Python 类,它表示了一组任务的集合以及这些任务应该如何被调度和执行。
一个典型的 DAG 包含以下元素:
任务(Tasks):DAG 中的基本单元,代表一个具体的执行动作。任务可以是任何类型的操作,例如运行一段 Python 代码、执行 SQL 查询、传输文件等。任务是由 Operator(操作符)来实现的。
Operator(操作符):用于定义任务的行为。Airflow 提供了许多内置的操作符,如 BashOperator、PythonOperator、SQLAlchemyOperator 等,同时支持用户自定义操作符。
依赖关系(Dependencies):任务之间可以通过依赖关系来确定执行顺序。例如,任务 A 必须在任务 B 完成之后才能开始执行。
参数(Arguments):定义 DAG 的一些通用属性,如所有者的名称、重试策略、默认参数等。
下面是我们编写的 DAG 示例代码:
from datetime import datetime, timedelta
from airflow import DAG
from airflow.providers.apache.hdfs.sensors.web_hdfs import WebHdfsSensor
from airflow.providers.apache.hive.operators.hive import HiveOperator
from airflow.providers.apache.hdfs.hooks.webhdfs import WebHDFSHook
from airflow.operators.bash import BashOperator
from airflow.operators.python import BranchPythonOperator
# 在 Airflow Connection Manager 中配置好 HDFS 和 Hive 连接信息
webhdfs_conn_id = "hdfs_default"
hive_cli_conn_id = "hive_cli_default"
# hdfs host
hdfs_host = "hdfs://192.168.1.16:8020"
# 指定要检查的文件路径
default_input_filedir = "/data/jhiot/origin/db/iotdb/iot_data_incr"
# 定义 DAG 的默认参数
default_args = {
'owner': 'airflow',
'depends_on_past': False,
'start_date': datetime(2024, 9, 1),
'email_on_failure': False,
'email_on_retry': False,
'retries': 1,
'retry_delay': timedelta(minutes=5),
}
# 定义 DAG
dag = DAG(
dag_id='load_iot_data_incr_daily',
default_args=default_args,
schedule_interval='0 1 * * *', # 每日凌晨 1 点执行
catchup=False,
)
# 1. 检查 HDFS 上的目录是否存在
def get_previous_day():
"""获取前一天的日期字符串"""
return (datetime.now() - timedelta(days=1)).strftime('%Y-%m-%d')
# 1. 检查 HDFS 上的目录是否存在
def _check_hdfs_directory(**kwargs):
"""检查 HDFS 上的目录是否存在,并返回下一个任务的 ID"""
previous_day = get_previous_day()
hdfs = WebHDFSHook(webhdfs_conn_id=webhdfs_conn_id)
filepath = f'{default_input_filedir}/{previous_day}'
if hdfs.check_for_path(filepath):
return 'execute_sync_command'
else:
return 'create_hdfs_directory'
check_hdfs_directory = BranchPythonOperator(
task_id='check_hdfs_directory',
python_callable=_check_hdfs_directory,
provide_context=True,
dag=dag,
)
# 2. 如果目录不存在,则创建此目录
create_hdfs_directory = BashOperator(
task_id='create_hdfs_directory',
bash_command=f"hadoop fs -fs {hdfs_host} -mkdir -p {default_input_filedir}/{get_previous_day()}",
dag=dag,
)
# 3. 在服务器上执行 shell 命令
execute_sync_command = BashOperator(
task_id='execute_sync_command',
bash_command=f'''
python /mnt/data/datax/bin/datax.py /mnt/data/datax/job/iotdb.iot_data_incr.json -p "-DcollectDate={get_previous_day()}"
''',
dag=dag,
)
# 4. 执行 Hive HQL Load Data
load_to_hive = HiveOperator(
task_id='load_to_hive',
hive_cli_conn_id=hive_cli_conn_id,
hql=f"LOAD DATA INPATH '{default_input_filedir}/" + """{{ yesterday_ds }}' OVERWRITE INTO TABLE jhiot.ods_iot_data_incr partition (dt='{{ yesterday_ds }}');""",
dag=dag,
)
# 设置任务依赖
check_hdfs_directory >> [create_hdfs_directory, execute_sync_command]
create_hdfs_directory >> execute_sync_command
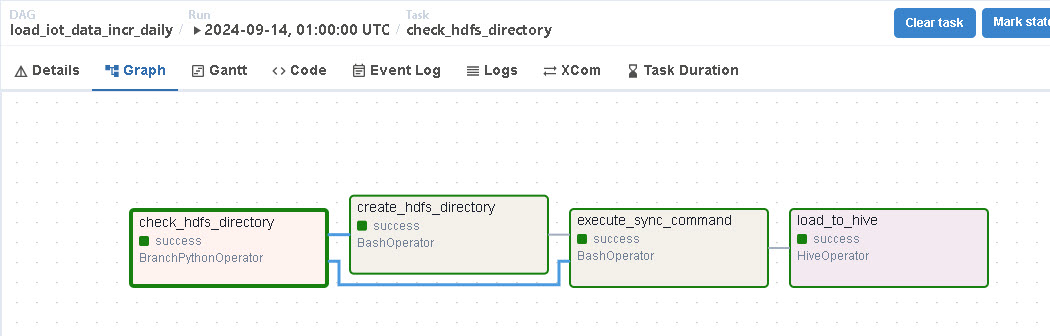
execute_sync_command >> load_to_hive在该 DAG 中,定义了如下几个任务(Task):
check_hdfs_directory:用于检查在 HDFS 上,以前一天的日期(如:2024-0-13)作为名称的目录是否存在;
create_hdfs_directory:通过 hadoop fs 命令在 {default_input_filedir} 目录下创建以前一天的日期作为名称的子目录;
execute_sync_command:主要通过 BaseOperator 执行 datax 工具命令实现从 MySQL 数据库中同步数据并写入HDFS的指定目录中;
load_to_hive:通过执行 Hive HQL Load Data 指令将 execute_sync_command 任务中写入的数据装载到指定的表 jhiot.ods_iot_data_incr 中;
并且这几个任务的依赖关系图如下:
下面我们需要将该 DAG 程序文件部署到 dags_folder 目录下,dags_folder 的配置如下:
zkj-server-05:~$ airflow config list | grep dags_folder
dags_folder = /mnt/data/airflow/dags
zkj-server-05:/mnt/data/airflow/dags$ ls -l dag-load-iot_data_dir-daily.py
-rw-r--r-- 1 zhikejia zhikejia 2925 Sep 14 19:56 dag-load-iot_data_dir-daily.py上面的 dag-load-iot_data_dir-daily.py 为我们的 DAG 文件。
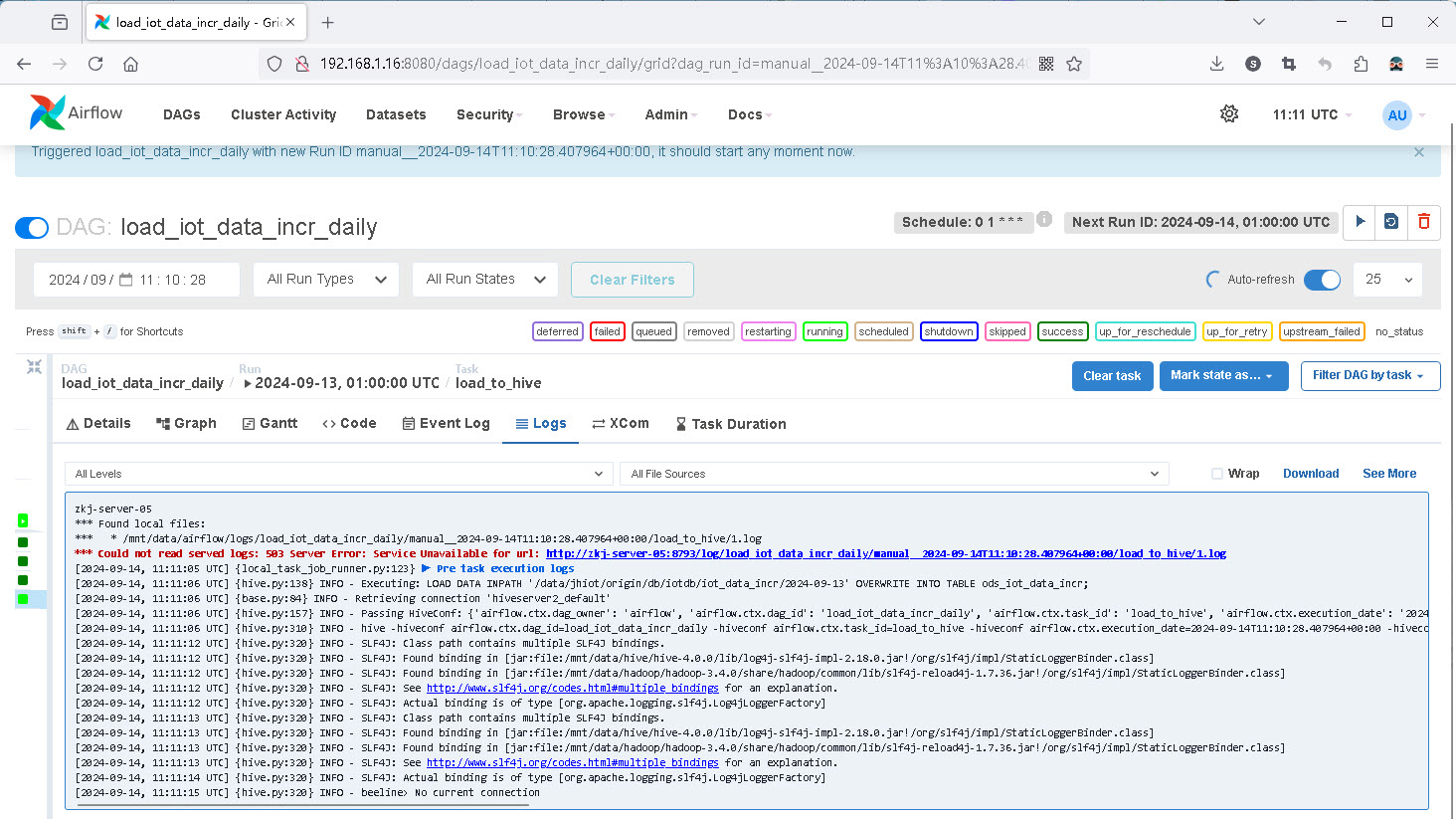
3.4 启动运行 DAG
在本示例中的 DAG(查看上面的 DAG 示例源码)是一个通过 schedule_interval 参数设置的每日凌晨1点执行的定时任务。这里为了演示,我们可以手动执行 DAG,下图为本示例 DAG 的详情页:
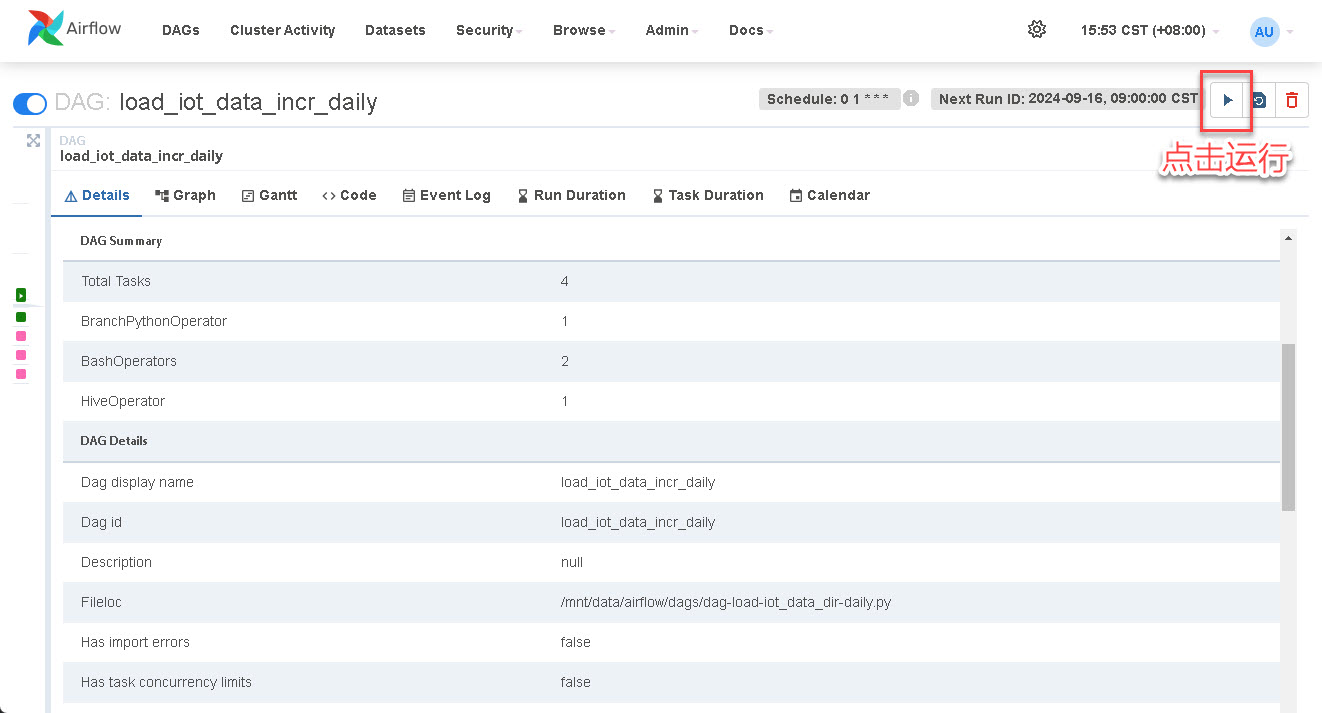
点击右上角的【运行】按钮,可以手动执行 DAG, 之后通过 Airflow Web UI 或者邮件等方式来监控任务状态,并在任务失败时发送通知。下图为 DAG 任务执行时 Web UI 上显示的任务(load_to_hive)日志,如果遇到问题,可以通过点击 download 下载任务执行的日志文件到本地来查看和分析日志: